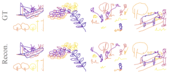|
|
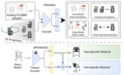
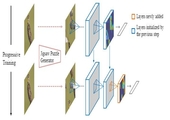
Freeview Sketching: View-Aware Fine-Grained Sketch-Based Image Retrieval
Aneeshan Sain, Pinaki Nath Chowdhury, Subhadeep Koley,
Ayan Kumar Bhunia, Yi-Zhe Song.
European Conference on Computer Vision (
ECCV
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
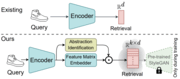
This paper addresses the intricate dynamics of Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) by focusing on the choice of viewpoint during sketch creation. It highlights the challenges faced by existing models when query-sketches differ in viewpoint from target instances. The paper proposes a view-aware system that accommodates both view-agnostic and view-specific tasks. The contributions include leveraging multi-view 2D projections of 3D objects, introducing a customisable cross-modal feature, and validating the approach through extensive experiments.
@InProceedings{FreeviewSketching,
author = {Aneeshan Sain and Pinaki Nath Chowdhury and Subhadeep Koley and Ayan Kumar Bhunia and Yi-Zhe Song},
title = {Freeview Sketching: View-Aware Fine-Grained Sketch-Based Image Retrieval},
booktitle = {European Conference on Computer Vision (ECCV)},
month = {June},
year = {2024}
}
|
|
|
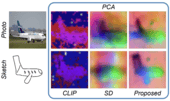
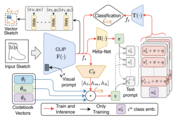
Do Generalised Classifiers Really Work on Human Drawn Sketches?
Hmrishav Bandyopadhyay, Pinaki Nath Chowdhury, Aneeshan Sain,
Subhadeep Koley, Tao Xiang, Ayan Kumar Bhunia, Yi-Zhe Song.
European Conference on Computer Vision (
ECCV
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
This paper investigates the effectiveness of generalised classifiers on human-drawn sketches, focusing on challenges such as varying levels of abstraction and generalisation across unseen categories. The study adapts CLIP, a large foundation model, to sketch-specific tasks by learning sketch-aware prompts and employing a codebook-driven approach to handle different abstraction levels. The results show that while there are improvements, generalisation across varying sketch abstractions remains an open challenge.
@InProceedings{GeneralisedClassifiers,
author = {Hmrishav Bandyopadhyay and Pinaki Nath Chowdhury and Aneeshan Sain and Subhadeep Koley and Tao Xiang and Ayan Kumar Bhunia and Yi-Zhe Song},
title = {Do Generalised Classifiers Really Work on Human Drawn Sketches?},
booktitle = {European Conference on Computer Vision (ECCV)},
month = {June},
year = {2024}
}
|
|
|
DemoCaricature: Democratising Caricature Generation with a Rough Sketch
Dar-Yen Chan, Ayan Kumar Bhunia, Subhadeep Koley, Pinaki Nath Chowdhury,
Aneeshan Sain,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
In this paper, we democratise caricature generation, empowering individuals to effortlessly craft personalised caricatures with just a photo and a conceptual sketch. Our objective is to strike a delicate balance between abstraction and identity, while preserving the creativity and subjectivity inherent in a sketch. To achieve this, we present Explicit Rank-1 Model Editing alongside single-image personalisation, selectively applying nuanced edits to cross-attention layers for a seamless merge of identity and style. Additionally, we propose Random Mask Reconstruction to enhance robustness, directing the model to focus on distinctive identity and style features. Crucially, our aim is not to replace artists but to eliminate accessibility barriers, allowing enthusiasts to engage in the artistry.
@InProceedings{DemoCaricature,
author = {Dar-Yen Chen and Ayan Kumar Bhunia and Subhadeep Koley and Aneeshan Sain and Pinaki Nath Chowdhury and Yi-Zhe Song},
title = {DemoCaricature: Democratising Caricature Generation with a Rough Sketch},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
It's All About Your Sketch: Democratising Sketch Control in Diffusion Models
Subhadeep Koley, Ayan Kumar Bhunia, Deeptanshu Sekhri,
Aneeshan Sain, Pinaki Nath Chowdhury, Tao Xiang,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
This paper unravels the potential of sketches for diffusion models, addressing the deceptive promise of direct sketch control in generative AI. We importantly democratise the process, enabling amateur sketches to generate precise images, living up to the commitment of "what you sketch is what you get". A pilot study underscores the necessity, revealing that deformities in existing models stem from spatial-conditioning. To rectify this, we propose an abstraction-aware framework, utilising a sketch adapter, adaptive time-step sampling, and discriminative guidance from a pre-trained fine-grained sketch-based image retrieval model, working synergistically to reinforce fine-grained sketch-photo association. Our approach operates seamlessly during inference without the need for textual prompts; a simple, rough sketch akin to what you and I can create suffices! We welcome everyone to examine results presented in the paper and its supplementary. Contributions include democratising sketch control, introducing an abstraction-aware framework, and leveraging discriminative guidance, validated through extensive experiments.
@InProceedings{StableSketching,
author = {Subhadeep Koley and Ayan Kumar Bhunia and Deeptanshu Sekhri, and Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {It's All About Your Sketch: Democratising Sketch Control in Diffusion Models},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
Subhadeep Koley
}
|
|
|
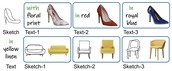
You’ll Never Walk Alone: A Sketch and Text Duet for
Fine-Grained Image Retrieval
Subhadeep Koley, Ayan Kumar Bhunia,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
Two primary input modalities prevail in image retrieval: sketch and text. While text is widely used for inter-category retrieval tasks, sketches have been established as the sole preferred modality for fine-grained image retrieval due to their ability to capture intricate visual details. In this paper, we question the reliance on sketches alone for fine-grained image retrieval by simultaneously exploring the fine-grained representation capabilities of both sketch and text, orchestrating a duet between the two. The end result enables precise retrievals previously unattainable, allowing users to pose ever-finer queries and incorporate attributes like colour and contextual cues from text. For this purpose, we introduce a novel compositionality framework, effectively combining sketches and text using pre-trained CLIP models, while eliminating the need for extensive fine-grained textual descriptions. Last but not least, our system extends to novel applications in composite image retrieval, domain attribute transfer, and fine-grained generation, providing solutions for various real-world scenarios.
@InProceedings{Sketch&TextFGSBIR,
author = {Subhadeep Koley and Ayan Kumar Bhunia and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {You’ll Never Walk Alone: A Sketch and Text Duet for
Fine-Grained Image Retrieval},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
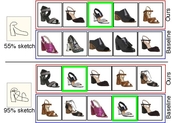
How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?
Subhadeep Koley, Ayan Kumar Bhunia,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
In this paper, we propose a novel abstraction-aware sketch-based image retrieval framework capable of handling sketch abstraction at varied levels. Prior works had mainly focused on tackling sub-factors such as drawing style and order, we instead attempt to model abstraction as a whole, and propose feature-level and retrieval granularity-level designs so that the system builds into its DNA the necessary means to interpret abstraction. On learning abstraction-aware features, we for the first-time harness the rich semantic embedding of pre-trained StyleGAN model, together with a novel abstraction-level mapper that deciphers the level of abstraction and dynamically selects appropriate dimensions in the feature matrix correspondingly, to construct a feature matrix embedding that can be freely traversed to accommodate different levels of abstraction. For granularity-level abstraction understanding, we dictate that the retrieval model should not treat all abstraction-levels equally and introduce a differentiable surrogate
Acc@q loss to inject that understanding into the system. Different to the gold-standard triplet loss, our
loss uniquely allows a sketch to narrow/broaden its focus in terms of how stringent the evaluation should be -- the more abstract a sketch, the less stringent (higher
). Extensive experiments depict our method to outperform existing state-of-the-arts in standard SBIR tasks along with challenging scenarios like early retrieval, forensic sketch-photo matching, and style-invariant retrieval.
@InProceedings{AbstractAway,
author = {Subhadeep Koley and Ayan Kumar Bhunia and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {How to Handle Sketch-Abstraction in Sketch-Based Image Retrieval?},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
SketchINR: A First Look into Sketches as Implicit Neural Representations
Hmrishav Bandyopadhyay, Ayan Kumar Bhunia , Pinaki Nath Chowdhury,
Aneeshan Sain,
Tao
Xiang
, Timothy Hospedales Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
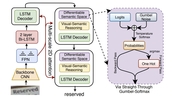
We propose SketchINR, to advance the representation of vector sketches with implicit neural models. A variable length vector sketch is compressed into a latent space of fixed dimension that implicitly encodes the underlying shape as a function of time and strokes. The learned function predicts the xy point coordinates in a sketch at each time and stroke. Despite its simplicity, SketchINR outperforms existing representations at multiple tasks: (i) Encoding an entire sketch dataset into a fixed size latent vector, SketchINR gives 60× and 10× data compression over raster and vector sketches, respectively. (ii) SketchINR's auto-decoder provides a much higher-fidelity representation than other learned vector sketch representations, and is uniquely able to scale to complex vector sketches such as FS-COCO. (iii) SketchINR supports parallelisation that can decode/render ∼100× faster than other learned vector representations such as SketchRNN. (iv) SketchINR, for the first time, emulates the human ability to reproduce a sketch with varying abstraction in terms of number and complexity of strokes. As a first look at implicit sketches, SketchINR's compact high-fidelity representation will support future work in modelling long and complex sketches.
@InProceedings{SketchINR,
author = {Hmrishav Bandyopadhyay and Ayan Kumar Bhunia and Pinaki Nath Chowdhury and Aneeshan Sain and Tao Xiang and Timothy Hospedales and Yi-Zhe Song},
title = {SketchINR: A First Look into Sketches as Implicit Neural Representations},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
Subhadeep Koley, Ayan Kumar Bhunia,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
This paper, for the first time, explores text-to-image diffusion models for Zero-Shot Sketch-based Image Retrieval (ZS-SBIR). We highlight a pivotal discovery: the capacity of text-to-image diffusion models to seamlessly bridge the gap between sketches and photos. This proficiency is underpinned by their robust cross-modal capabilities and shape bias, findings that are substantiated through our pilot studies. In order to harness pre-trained diffusion models effectively, we introduce a straightforward yet powerful strategy focused on two key aspects: selecting optimal feature layers and utilising visual and textual prompts. For the former, we identify which layers are most enriched with information and are best suited for the specific retrieval requirements (category-level or fine-grained). Then we employ visual and textual prompts to guide the model's feature extraction process, enabling it to generate more discriminative and contextually relevant cross-modal representations. Extensive experiments on several benchmark datasets validate significant performance improvements.
@InProceedings{DiffusionZSSBIR,
author = {Subhadeep Koley and Ayan Kumar Bhunia and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
What Sketch Explainability
Really Means for Downstream Tasks
Hmrishav Bandyopadhyay, Pinaki Nath Chowdhury, Ayan Kumar Bhunia,
Aneeshan Sain, Tao Xiang,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
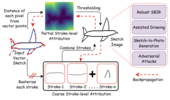
In this paper, we explore the unique modality of sketch for explainability, emphasising the profound impact of human strokes compared to conventional pixel-oriented studies. Beyond explanations of network behavior, we discern the genuine implications of explainability across diverse downstream sketch-related tasks. We propose a lightweight and portable explainability solution -- a seamless plugin that integrates effortlessly with any pre-trained model, eliminating the need for re-training. Demonstrating its adaptability, we present four applications: highly studied retrieval and generation, and completely novel assisted drawing and sketch adversarial attacks. The centrepiece to our solution is a stroke-level attribution map that takes different forms when linked with downstream tasks. By addressing the inherent non-differentiability of rasterisation, we enable explanations at both coarse stroke level (SLA) and partial stroke level (P-SLA), each with its advantages for specific downstream tasks.
@InProceedings{DemoCaricature,
author = {Hmrishav Bandyopadhyay and Pinaki Nath Chowdhury and Ayan Kumar Bhunia and Aneeshan Sain and Pinaki Nath Chowdhury and Yi-Zhe Song},
title = {What Sketch Explainability Really Means for Downstream Tasks},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes
Hmrishav Bandyopadhyay, Subhadeep Koley, Ayan Das, Ayan Kumar Bhunia,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2024
Abstract
/
Code
/
arXiv
/
BibTex
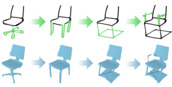
In this paper, we democratise 3D content creation, enabling precise generation of 3D shapes from abstract sketches while overcoming limitations tied to drawing skills. We introduce a novel part-level modelling and alignment framework that facilitates abstraction modelling and cross-modal correspondence. Leveraging the same part-level decoder, our approach seamlessly extends to sketch modelling by establishing correspondence between CLIPasso edgemaps and projected 3D part regions, eliminating the need for a dataset pairing human sketches and 3D shapes. Additionally, our method introduces a seamless in-position editing process as a byproduct of cross-modal part-aligned modelling. Operating in a low-dimensional implicit space, our approach significantly reduces computational demands and processing time.
@InProceedings{Doodle-to-3D,
author = {Hmrishav Bandyopadhyay and Subhadeep Koley and Ayan Das and Ayan Kumar Bhunia and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
|
|
|
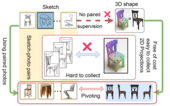
Democratising 2D Sketch to 3D Shape Retrieval Through Pivoting
Pinaki Nath Chowdhury,
Ayan Kumar Bhunia,
Aneeshan Sain, Subhadeep Koley,
Tao
Xiang
, Yi-Zhe Song
.
International Conference on Computer Vision (
ICCV
),
2023.
Abstract
/
Code
/
arXiv
/
BibTex
Human sketch has already proved its worth in various visual understanding tasks (e.g.,
retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of
sketches -- that they are also salient. This is intuitive as sketching is a natural
attentive
process at its core. More specifically, we aim to study how sketches can be used as a weak
label to detect salient objects present in an image. To this end, we propose a novel method
that emphasises on how “salient object” could be explained by hand-drawn sketches. To
accomplish this, we introduce a photo-to-sketch generation model that aims to generate
sequential sketch coordinates corresponding to a given visual photo through a 2D attention
mechanism. Attention maps accumulated across the time steps give rise to salient regions in
the process. Extensive quantitative and qualitative experiments prove our hypothesis and
delineate how our sketch-based saliency detection model gives a competitive performance
compared to the state-of-the-art.
@InProceedings{Sketch2Saliency,
author = {Pinaki Nath Chowdhury and Ayan Kumar Bhunia and
Aneeshan Sain and Subhadeep Koley and Tao Xiang and Yi-Zhe Song},
title = {Democratising 2D Sketch to 3D Shape Retrieval Through Pivoting},
booktitle = {International Conference on Computer Vision (ICCV)},
month = {Oct},
year = {2023}
}
|
|
|
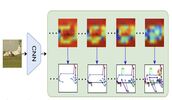
Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings
Ayan Kumar Bhunia
, Subhadeep Koley, Amandeep Kumar,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023
Abstract
/
Code
/
arXiv
/
BibTex
Human sketch has already proved its worth in various visual understanding tasks (e.g.,
retrieval, segmentation, image-captioning, etc). In this paper, we reveal a new trait of
sketches -- that they are also salient. This is intuitive as sketching is a natural
attentive
process at its core. More specifically, we aim to study how sketches can be used as a weak
label to detect salient objects present in an image. To this end, we propose a novel method
that emphasises on how “salient object” could be explained by hand-drawn sketches. To
accomplish this, we introduce a photo-to-sketch generation model that aims to generate
sequential sketch coordinates corresponding to a given visual photo through a 2D attention
mechanism. Attention maps accumulated across the time steps give rise to salient regions in
the process. Extensive quantitative and qualitative experiments prove our hypothesis and
delineate how our sketch-based saliency detection model gives a competitive performance
compared to the state-of-the-art.
@InProceedings{Sketch2Saliency,
author = {Ayan Kumar Bhunia and Subhadeep Koley and Amandeep Kumar and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Sketch2Saliency: Learning to Detect Salient Objects from Human Drawings},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Subhadeep Koley,
Ayan Kumar Bhunia
,
Aneeshan Sain, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023
Abstract
/
Code
/
arXiv
/
BibTex
Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me,
this
paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all
non-cherry-picked. We differ significantly to prior art in that we do not dictate an
edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches.
In
doing so, we essentially democratise the sketch-to-photo pipeline, ''picturing'' a sketch
regardless of how good you sketch. Our contribution at the outset is a decoupled
encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only.
This importantly ensures generated results are always photorealistic. The rest is then all
centred around how best to deal with the abstraction gap between sketch and photo. For that,
we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch
to
the StyleGAN latent space. We further introduce specific designs to tackle the abstract
nature
of human sketches, including a fine-grained discriminative loss on the back of a trained
sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we
showcase a few downstream tasks our generation model enables, amongst them is showing how
fine-grained sketch-based image retrieval, a well-studied problem in the sketch community,
can
be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We
put forward generated results in the supplementary for everyone to scrutinise.
@InProceedings{PictureThatSketch,
author = {Subhadeep Koley and Ayan Kumar Bhunia and
Aneeshan Sain and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Picture that Sketch: Photorealistic Image Generation from Abstract Sketches},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
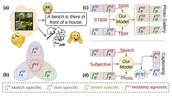
SceneTrilogy: On Human Scene-Sketch and its Complementarity with Photo and Text
Pinaki Nath Chowdhury,
Ayan Kumar Bhunia
, Aneeshan Sain, Subhadeep Koley,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023
Abstract
/
Code
/
arXiv
/
BibTex
In this paper, we extend scene understanding to include that of human sketch. The result
is
a complete trilogy of scene representation from three diverse and complementary {modalities}
-- sketch, photo, and text. Instead of learning a rigid three-way embedding and be done with
it, we focus on learning a flexible joint embedding that fully supports the ``optionality"
that this complementarity brings. Our embedding supports optionality on two axis: (i)
optionality across modalities -- use any combination of modalities as query for downstream
tasks like retrieval, (ii) optionality across tasks -- simultaneously utilising the
embedding
for either discriminative (e.g., retrieval) or generative tasks (e.g., captioning). This
provides flexibility to end-users by exploiting the best of each modality, therefore serving
the very purpose behind our proposal of a trilogy at the first place. First, a combination
of
information-bottleneck and conditional invertible neural networks disentangle the
modality-specific component from modality-agnostic in sketch, photo, and text. Second, the
modality-agnostic instances from sketch, photo, and text are synergised using a modified
cross-attention. Once learned, we show our embedding can accommodate a multi-facet of
scene-related tasks, including those enabled for the first time by the inclusion of sketch,
all without any task-specific modifications.
@InProceedings{SceneTrilogy,
author = {Pinaki Nath Chowdhury and Ayan Kumar Bhunia and
Aneeshan Sain and Subhadeep Koley and Tao Xiang and Yi-Zhe Song},
title = {SceneTrilogy: On Human Scene-Sketch and its Complementarity with Photo and Text},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
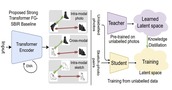
Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR
Aneeshan Sain,
Ayan Kumar Bhunia
, Subhadeep Koley, Pinaki Nath Chowdhury,
Soumitri Chattopadhyay,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023.
Abstract
/
Code
/
arXiv
/
BibTex
This paper advances the fine-grained sketch-based image retrieval (FG-SBIR) literature by
putting forward a strong baseline that overshoots prior state-of-the art by ~11%. This is
not
via
complicated design though, but by addressing two critical issues facing the community (i)
the
gold
standard triplet loss does not enforce holistic latent space geometry, and (ii) there are
never
enough sketches to train a high accuracy model. For the former, we propose a simple
modification
to the standard triplet loss, that explicitly enforces separation amongst photos/sketch
instances.
For the latter, we put forward a novel knowledge distillation module can leverage photo data
for
model training. Both modules are then plugged into a novel plug-n-playable training paradigm
that
allows for more stable training. More specifically, for (i) we employ an intra-modal triplet
loss
amongst sketches to bring sketches of the same instance closer from others, and one more
amongst
photos to push away different photo instances while bringing closer a structurally augmented
version of the same photo (offering a gain of 4-6%). To tackle (ii), we first pre-train a
teacher
on the large set of unlabelled photos over the aforementioned intra-modal photo triplet
loss.
Then
we distill the contextual similarity present amongst the instances in the teacher's
embedding
space to that in the student's embedding space, by matching the distribution over
inter-feature
distances of respective samples in both embedding spaces (delivering a further gain of
4-5%).
Apart from outperforming prior arts significantly, our model also yields satisfactory
results
on
generalising to new classes.
@InProceedings{Stronger_FGSBIR,
author = {Aneeshan Sain and Ayan Kumar Bhunia and
Subhadeep Koley and Pinaki Nath Chowdhury and Soumitri Chattopadhyay and Tao Xiang and Yi-Zhe
Song},
title = {Exploiting Unlabelled Photos for Stronger Fine-Grained SBIR},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
What Can Human Sketches Do for Object Detection?
Pinaki Nath Chowdhury,
Ayan Kumar Bhunia
, Aneeshan Sain, Subhadeep Koley,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023 [Top 12 Award Candidates]
Abstract
/
Code
/
arXiv
/
BibTex
Sketches are highly expressive, inherently capturing subjective and fine-grained visual
cues. The exploration of such innate properties of human sketches has however been limited
to
that of image retrieval. In this paper, for the first time, we cultivate the expressiveness
of
sketches, but for the fundamental vision task of object detection. The end result is
sketch-enabled object detection framework that detects based on what you sketch -- that
``zerbra'' (e.g., one that is eating the grass) in a herd of zebras (instance-ware
detection),
and only the part (e.g., ``head" of a ``zebra") that you desire (part-aware detection). We
further dictate that our model works without (i) knowing which category to expect at testing
(zero-shot), and (ii) not requiring additional bounding boxes (as per supervised), and class
labels (as per weakly supervised). Instead of devising a model from the ground up, we show
an
intuitive synergy between foundation models (e.g., CLIP) and existing sketch models build
for
sketch-based image retrieval (SBIR), can already elegantly solve the task -- CLIP to provide
model generalisation, and SBIR to bridge the (sketch
photo) gap. In particular, we first perform independent prompting on both sketch and photo
branches of a SBIR model, to build highly generalisable sketch and photo encoders on the
back
of the generalisation ability of CLIP. We then devise a training paradigm to adapt the
learned
encoders for object detection, such that the region embeddings of detected boxes are aligned
with the sketch and photo embeddings from SBIR. Evaluating our framework on standard object
detection datasets like PASCAL-VOC and MS-COCO outperforms both supervised (SOD) and weakly
supervise.
@InProceedings{Sketch_FineGrained_ObjectDet,
author = {Pinaki Nath Chowdhury and Ayan Kumar Bhunia and Aneeshan Sain and
Subhadeep Koley and Tao Xiang and Yi-Zhe Song},
title = {What Can Human Sketches Do for Object Detection?},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Aneeshan Sain,
Ayan Kumar Bhunia
, Pinaki Nath Chowdhury, Subhadeep Koley,
Tao
Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023
Abstract
/
Code
/
arXiv
/
BibTex
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We
are largely inspired by recent advances on foundation models and the unparalleled
generalisation ability they seem to offer, but for the first time tailor it to benefit the
sketch community. We put forward novel designs on how best to achieve this synergy, for both
the category setting and the fine-grained setting (''all''). At the very core of our
solution
is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we
already have a category-level ZS-SBIR system that overshoots all prior arts, by a large
margin
(24.8%) -- a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the
fine-grained setup is however trickier, and requires a deeper dive into this synergy. For
that, we come up with two specific designs to tackle the fine-grained matching nature of the
problem: (i) an additional regularisation loss to ensure the relative separation between
sketches and photos is uniform across categories, which is not the case for the gold
standard
standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing
instance-level structural correspondences between sketch-photo pairs. With these designs, we
again observe significant performance gains in the region of 26.9% over previous
state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning
paradigm carries great promise in tackling other sketch-related tasks (not limited to
ZS-SBIR)
where data scarcity remains a great challenge.
@InProceedings{ZSSBIR_CLIP,
author = { Aneeshan Sain and Ayan Kumar Bhunia and Pinaki Nath Chowdhury and Aneeshan Sain and
Subhadeep Koley and Tao Xiang and Yi-Zhe Song},
title = {
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
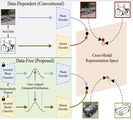
Data-Free Sketch-Based Image Retrieval
Abhra Chaudhuri,
Ayan Kumar Bhunia
, Yi-Zhe Song,
Anjan Dutta
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2023
Abstract
/
Code
/
arXiv
/
BibTex
Rising concerns about privacy and anonymity preservation of deep learning models have
facilitated research in data-free learning. Primarily based on data-free knowledge
distillation, models developed in this area so far have only been able to operate in a
single
modality, performing the same kind of task as that of the teacher. For the first time, we
propose Data-Free Sketch-Based Image Retrieval (DF-SBIR), a cross-modal data-free learning
setting, where teachers trained for classification in a single modality have to be leveraged
by students to learn a cross-modal metric-space for retrieval. The widespread availability
of
pre-trained classification models, along with the difficulty in acquiring paired
photo-sketch
datasets for SBIR justify the practicality of this setting. We present a methodology for
DF-SBIR, which can leverage knowledge from models independently trained to perform
classification on photos and sketches. We perform extensive empirical evaluation of our
model
on the Sketchy and TU-Berlin benchmarks, designing a variety of baselines based on existing
data-free learning literature, and observe that our method surpasses all of them by
significant margins. Our method also achieves mAPs competitive with data-dependent
approaches,
all the while requiring no training data. Implementation will be made publicly available
upon
acceptance.
@InProceedings{DataFree_SBIR,
author = { Abhra Chaudhuri and Ayan Kumar Bhunia and Yi-Zhe Song and Anjan Dutta},
title = {Data-Free Sketch-Based Image Retrieval},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023}
}
|
|
|
FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in
Context
Pinaki Nath Chowdhury, Aneeshan Sain,
Yulia Gryaditskaya,
Ayan Kumar Bhunia
,
Tao
Xiang
, Yi-Zhe Song
.
European Conference on Computer Vision(
ECCV
),
2022
Abstract
/
Code
/
arXiv
/
BibTex
We advance sketch research to scenes with the first dataset of freehand scene sketches,
FS-COCO. With practical applications in mind, we collect sketches that convey well scene
content but can be sketched within a few minutes by a person with any sketching skills. Our
dataset comprises 10,000 freehand scene vector sketches with per point space-time
information
by 100 non-expert individuals, offering both object- and scene-level abstraction. Each
sketch
is augmented with its text description. Using our dataset, we study for the first time the
problem of fine-grained image retrieval from freehand scene sketches and sketch captions. We
draw insights on: (i) Scene salience encoded in sketches using the strokes temporal order;
(ii) Performance comparison of image retrieval from a scene sketch and an image caption;
(iii)
Complementarity of information in sketches and image captions, as well as the potential
benefit of combining the two modalities. In addition, we extend a popular vector sketch
LSTM-based encoder to handle sketches with larger complexity than was supported by previous
work. Namely, we propose a hierarchical sketch decoder, which we leverage at a
sketch-specific
“pre-text” task. Our dataset enables for the first time research on freehand scene sketch
understanding and its practical applications
@InProceedings{FSCOCO,
author = {Pinaki Nath Chowdhury and Aneeshan Sain and Yulia Gryaditskaya and Ayan Kumar Bhunia
and
and Tao Xiang and Yi-Zhe Song},
title = {FS-COCO: Towards Understanding of Freehand Sketches
of Common Objects in Context},
booktitle = {ECCV},
month = {October},
year = {2022}
}
|
|
|
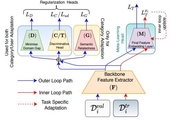
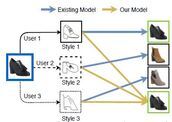
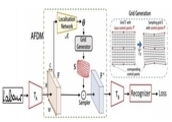
Adaptive Fine-Grained Sketch-Based Image Retrieval
Ayan Kumar Bhunia
, Aneeshan Sain, Parth Hiren Shah,
Animesh Gupta, Pinaki Nath Chowdhury,
Tao
Xiang
, Yi-Zhe Song
.
European Conference on Computer Vision(
ECCV
),
2022
Abstract
/
Code
/
arXiv
/
BibTex
The recent focus on Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) has shifted
towards
generalising a model to new categories without any training data from them. In real-world
applications, however, a trained FG-SBIR model is often applied to both new categories and
different human sketchers, i.e., different drawing styles. Although this complicates the
generalisation problem, fortunately, a handful of examples are typically available, enabling
the model to adapt to the new category/style. In this paper, we offer a novel perspective --
instead of asking for a model that generalises, we advocate for one that quickly adapts,
with
just very few samples during testing (in a few-shot manner). To solve this new problem, we
introduce a novel model-agnostic meta-learning (MAML) based framework with several key
modifications: (1) As a retrieval task with a margin-based contrastive loss, we simplify the
MAML training in the inner loop to make it more stable and tractable. (2) The margin in our
contrastive loss is also meta-learned with the rest of the model. (3) Three additional
regularisation losses are introduced in the outer loop, to make the meta-learned FG-SBIR
model
more effective for category/style adaptation. Extensive experiments on public datasets
suggest
a large gain over generalisation and zero-shot based approaches, and a few strong few-shot
baselines..
@InProceedings{adaptivefgsbir,
author = {Ayan Kumar Bhunia and Aneeshan Sain and Parth Hiren Shah and Animesh Gupta and
Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Adaptive Fine-Grained Sketch-Based Image Retrieval},
booktitle = {ECCV},
month = {October},
year = {2022}
}
|
|
|
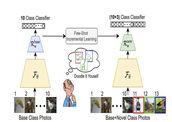
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches
Ayan Kumar Bhunia
, Viswanatha Reddy Gajjala, Subhadeep Koley,
Rohit Kundu, Aneeshan Sain, Tao Xiang
, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2022
Abstract
/
Code
/
arXiv
/
Marktechpost Blog
/
BibTex
The human visual system is remarkable in learning new visual concepts from just a few
examples. This is precisely the goal behind few-shot class incremental learning (FSCIL),
where
the emphasis is additionally placed on ensuring the model does not suffer from
``forgetting''.
{In this paper, we push the boundary further for FSCIL by addressing} two key questions that
bottleneck its ubiquitous application (i) can the model learn from diverse modalities other
than just photo (as humans do), and (ii) what if photos are not readily accessible (due to
ethical and privacy constraints). Our key innovation lies in advocating the use of sketches
as
a new modality for class support. The product is a ``Doodle It Yourself" (DIY) FSCIL
framework
where the users can freely sketch a few examples of a novel class for the model to learn to
recognize photos of that class. For that, we present a framework that infuses (i) gradient
consensus for domain invariant learning, (ii) knowledge distillation for preserving old
class
information, and (iii) graph attention networks for message passing between old and novel
classes. We experimentally show that sketches are better class support than text in the
context of FSCIL, echoing findings elsewhere in the sketching literature.
@InProceedings{DoodleIncremental,
author = {Ayan Kumar Bhunia and Viswanatha Reddy Gajjala and Subhadeep Koley and Rohit Kundu
and
Aneeshan Sain and Tao Xiang and Yi-Zhe Song},
title = {Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}
}
|
|
|
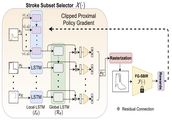
Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval
Ayan Kumar Bhunia
, Subhadeep Koley, Abdullah Faiz Ur Rahman Khilji
, Aneeshan Sain, Pinaki Nath Chowdhury, Tao
Xiang, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2022
Abstract
/
Code
/
arXiv
/
BibTex
Sketching enables many exciting applications, notably, image retrieval. The
fear-to-sketch problem (i.e., ``I can't sketch") has however proven to be fatal for its
widespread adoption. This paper tackles this ``fear" head on, and for the first time,
proposes an auxiliary module for existing retrieval models that predominantly lets the users
sketch without having to worry. We first conducted a pilot study that revealed the secret
lies in the existence of noisy strokes, but not so much of the ``I can't sketch". We
consequently design a stroke subset selector that {detects noisy strokes, leaving only
those} which make a positive contribution towards successful retrieval. Our Reinforcement
Learning based formulation quantifies the importance of each stroke present in a given
subset, based on the extend to which that stroke contributes to retrieval. When combined
with pre-trained retrieval models as a pre-processing module, we achieve a significant gain
of 8\%-10\% over standard baselines and in turn report new state-of-the-art performance.
Last but not least, we demonstrate the selector once trained, can also be used in a
plug-and-play manner to empower various sketch applications in ways that were not previously
possible.
@InProceedings{strokesubset,
author = {Ayan Kumar Bhunia and Subhadeep Koley and Abdullah Faiz Ur Rahman Khilji and
Aneeshan Sain
and Pinaki Nath Chowdhury and Tao Xiang and Yi-Zhe Song},
title = {Sketching without Worrying: Noise-Tolerant Sketch-Based Image Retrieval},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}
}
|
|
|
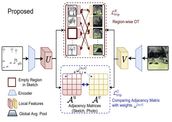
Partially Does It: Towards Scene-Level FG-SBIR with Partial Input
Pinaki Nath Chowdhury,
Ayan Kumar Bhunia
, Viswanatha Reddy Gajjala, Aneeshan Sain,
Tao Xiang, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2022
Abstract
/
Code
/
arXiv
/
BibTex
We scrutinise an important observation plaguing scene-level sketch research -- that a
significant portion of scene sketches are ``partial". A quick pilot study reveals: (i) a
scene
sketch does not necessarily contain all objects in the corresponding photo, due to the
subjective holistic interpretation of scenes, (ii) there exists significant empty (white)
regions as a result of object-level abstraction, and as a result, (iii) existing scene-level
fine-grained sketch-based image retrieval methods collapse as scene sketches become more
partial. To solve this ``partial" problem, we advocate for a simple set-based approach using
optimal transport (OT) to model cross-modal region associativity in a partially-aware
fashion.
Importantly, we improve upon OT to further account for holistic partialness by comparing
intra-modal adjacency matrices. Our proposed method is not only robust to partial
scene-sketches but also yields state-of-the-art performance on existing datasets.
@InProceedings{PartialSBIR,
author = {Pinaki Nath Chowdhury and Ayan Kumar Bhunia and Viswanatha Reddy Gajjala and
Aneeshan
Sain and Tao Xiang and Yi-Zhe Song},
title = {Partially Does It: Towards Scene-Level FG-SBIR with Partial Input},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}
}
|
|
|
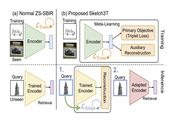
Sketch3T: Test-time Training for Zero-Shot SBIR
Aneeshan Sain,
Ayan Kumar Bhunia
, Vaishnav Potlapalli , Pinaki Nath Chowdhury
,
Tao Xiang, Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2022
Abstract
/
Code
/
arXiv
/
BibTex
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied
as
is to unseen categories. In this paper, we question to argue that this setup by definition
is
not compatible with the inherent abstract and subjective nature of sketches -- the model
might
transfer well to new categories, but will not understand sketches existing in different
test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both
categories and sketch distributions. Our key contribution is a test-time training paradigm
that can adapt using just one sketch. Since there is no paired photo, we make use of a
sketch
raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the
fidelity of the trained cross-modal joint embedding during test-time update, we design a
novel
meta-learning based training paradigm to learn a separation between model updates incurred
by
this auxiliary task from those off the primary objective of discriminative learning.
Extensive
experiments show our model to outperform state-of-the-arts, thanks to the proposed test-time
adaption that not only transfers to new categories but also accommodates to new sketching
styles.
@InProceedings{Sketch3T,
author = {Aneeshan Sain and Ayan Kumar Bhunia and Vaishnav Potlapalli and Pinaki Nath
Chowdhury
and Tao Xiang and Yi-Zhe Song},
title = {Sketch3T: Test-time Training for Zero-Shot SBIR},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022}
}
|
|
|
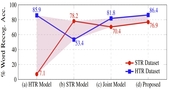
Text is Text, No Matter What: Unifying Text Recognition using Knowledge
Distillation
Ayan Kumar Bhunia
, Aneeshan Sain, Pinaki Nath Chowdhury,
Yi-Zhe Song
.
IEEE International Conference on Computer Vision (
ICCV
),
2021
Abstract
/
arXiv
/
BibTex
Text recognition remains a fundamental and extensively researched topic in computer
vision,
largely owing to its wide array of commercial applications. The challenging nature of the
very
problem however dictated a fragmentation of research efforts: Scene Text Recognition (STR)
that
deals with text in everyday scenes, and Handwriting Text Recognition (HTR) that tackles
hand-written text. In this paper, for the first time, we argue for their unification -- we
aim
for a single model that can compete favourably with two separate state-of-the-art STR and
HTR
models. We first show that cross-utilisation of STR and HTR models trigger significant
performance drops due to differences in their inherent challenges. We then tackle their
union
by
introducing a knowledge distillation (KD) based framework. This is however non-trivial,
largely
due to the variable-length and sequential nature of text sequences, which renders
off-the-shelf
KD techniques that mostly works with global fixed length data inadequate. For that, we
propose
three distillation losses all of which specifically designed to cope with the aforementioned
unique characteristics of text recognition. Empirical evidence suggests that our proposed
unified model performs on par with individual models, even surpassing them in certain cases.
Ablative studies demonstrates that naive baselines such as a two-stage framework, and domain
adaption/generalisation alternatives do not work as well, further verifying the
appropriateness
of our design.
@InProceedings{textistext,
author = {Ayan Kumar Bhunia and Aneeshan Sain and Pinaki Nath Chowdhury and Yi-Zhe Song},
title = {Text is Text, No Matter What: Unifying Text Recognition using Knowledge
Distillation},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021}
}
|
|
|
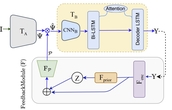
Towards the Unseen: Iterative Text Recognition by Distilling from Errors
Ayan Kumar Bhunia
, Pinaki Nath Chowdhury, Aneeshan Sain,
Yi-Zhe Song
.
IEEE International Conference on Computer Vision (
ICCV
),
2021
Abstract
/
arXiv
/
BibTex
Visual text recognition is undoubtedly one of the most extensively researched topics in
computer vision. Great progress have been made to date, with the latest models starting to
focus
on the more practical ``in-the-wild'' setting. However, a salient problem still hinders
practical deployment -- prior arts mostly struggle with recognising unseen (or rarely seen)
character sequences. In this paper, we put forward a novel framework to specifically tackle
this
``unseen'' problem. Our framework is iterative in nature, in that it utilises predicted
knowledge of character sequences from a previous iteration, to augment the main network in
improving the next prediction. Key to our success is a unique cross-modal variational
autoencoder to act as a feedback module, which is trained with the presence of textual error
distribution data. This module importantly translate a discrete predicted character space,
to
a
continuous affine transformation parameter space used to condition the visual feature map at
next iteration. Experiments on common datasets have shown competitive performance over
state-of-the-arts under the conventional setting. Most importantly, under the new disjoint
setup
where train-test labels are mutually exclusive, ours offers the best performance thus
showcasing
the capability of generalising onto unseen words.
@InProceedings{towardsunseen,
author = {Ayan Kumar Bhunia and Pinaki Nath Chowdhury and Aneeshan Sain and Yi-Zhe Song},
title = {Towards the Unseen: Iterative Text Recognition by Distilling from Errors},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021}
}
|
|
|
Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition
Ayan Kumar Bhunia
, Aneeshan Sain,
Amandeep Kumar, Shuvozit Ghose, Pinaki
Nath
Chowdhury,
Yi-Zhe Song
.
IEEE International Conference on Computer Vision (
ICCV
),
2021
Abstract
/
arXiv
/
BibTex
Although text recognition has significantly evolved over the years, state-of the-art
(SOTA)
models still struggle in the wild scenarios due to complex backgrounds, varying fonts,
uncontrolled illuminations, distortions and other artifacts. This is because such models
solely
depend on visual information for text recognition, thus lacking semantic reasoning
capabilities.
In this paper, we argue that semantic information offers a complimentary role in addition
to
visual only. More specifically, we additionally utilize semantic information by proposing
a
multi-stage multi-scale attentional decoder that performs joint visual-semantic reasoning.
Our
novelty lies in the intuition that for text recognition, prediction should be refined in a
stage-wise manner. Therefore our key contribution is in designing a stage-wise unrolling
attentional decoder where non-differentiability, invoked by discretely predicted character
labels, needs to be bypassed for end-to-end training. While the first stage predicts using
visual features, subsequent stages refine on-top of it using joint visual-semantic
information.
Additionally, we introduce multi-scale 2D attention along with dense and residual
connections
between different stages to deal with varying scales of character sizes, for better
performance
and faster convergence during training. Experimental results show our approach to
outperform
existing SOTA methods by a considerable margin.
@InProceedings{JVSR,
author = {Ayan Kumar Bhunia and Aneeshan Sain and Amandeep Kumar and Shuvozit Ghose and
Pinaki
Nath Chowdhury and Yi-Zhe Song},
title = {Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021}
}
|
|
|
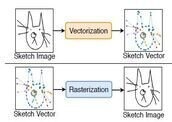
Vectorization and Rasterization: Self-Supervised Learning for Sketch and
Handwriting
Ayan Kumar Bhunia
, Pinaki Nath Chowdhury, Yongxin Yang,
Timothy Hospedales, Tao Xiang,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2021
Abstract
/
Code
/
arXiv
/
BibTex
Self-supervised learning has gained prominence due to its efficacy at learning powerful
representations from unlabelled data that achieve excellent performance on many challenging
downstream tasks. However supervision-free pre-text tasks are challenging to design and
usually
modality specific. Although there is a rich literature of self-supervised methods for either
spatial (such as images) or temporal data (sound or text) modalities, a common pre-text task
that benefits both modalities is largely missing. In this paper, we are interested in
defining
a
self-supervised pre-text task for sketches and handwriting data. This data is uniquely
characterised by its existence in dual modalities of rasterized images and vector coordinate
sequences. We address and exploit this dual representation by proposing two novel
cross-modal
translation pre-text tasks for self-supervised feature learning: Vectorization and
Rasterization. Vectorization learns to map image space to vector coordinates and
rasterization
maps vector coordinates to image space. We show that the our learned encoder modules benefit
both raster-based and vector-based downstream approaches to analysing hand-drawn data.
Empirical
evidence shows that our novel pre-text tasks surpass existing single and multi-modal
self-supervision methods.
@InProceedings{sketch2vec,
author = {Ayan Kumar Bhunia and Pinaki Nath Chowdhury and Yongxin Yang and Timothy Hospedales
and
Tao Xiang and Yi-Zhe Song},
title = {Vectorization and Rasterization: Self-Supervised Learning for Sketch and
Handwriting},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}
|
|
|
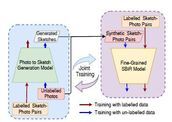
More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch
Based Image Retrieval
Ayan Kumar Bhunia
, Pinaki Nath Chowdhury, Aneeshan Sain,
Yongxin Yang, Tao Xiang,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2021
Abstract
/
Code
/
arXiv
/
BibTex
A fundamental challenge faced by existing Fine-Grained Sketch-Based Image Retrieval
(FG-SBIR)
models is the data scarcity -- model performances are largely bottlenecked by the lack of
sketch-photo pairs. Whilst the number of photos can be easily scaled, each corresponding
sketch
still needs to be individually produced. In this paper, we aim to mitigate such an
upper-bound
on sketch data, and study whether unlabelled photos alone (of which they are many) can be
cultivated for performances gain. In particular, we introduce a novel semi-supervised
framework
for cross-modal retrieval that can additionally leverage large-scale unlabelled photos to
account for data scarcity. At the centre of our semi-supervision design is a sequential
photo-to-sketch generation model that aims to generate paired sketches for unlabelled
photos.
Importantly, we further introduce a discriminator guided mechanism to guide against
unfaithful
generation, together with a distillation loss based regularizer to provide tolerance against
noisy training samples. Last but not least, we treat generation and retrieval as two
conjugate
problems, where a joint learning procedure is devised for each module to mutually benefit
from
each other. Extensive experiments show that our semi-supervised model yields significant
performance boost over the state-of-the-art supervised alternatives, as well as existing
methods
that can exploit unlabelled photos for FG-SBIR.
@InProceedings{semi-fgsbir,
author = {Ayan Kumar Bhunia and Pinaki Nath Chowdhury and Aneeshan Sain and Yongxin Yang and
Tao
Xiang and Yi-Zhe Song},
title = {More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based
Image Retrieval},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}
|
|
|
StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
Aneeshan Sain,
Ayan Kumar Bhunia
,
Yongxin Yang and ,
Tao Xiang,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2021
Abstract
/
arXiv
/
BibTex
Sketch-based image retrieval (SBIR) is a cross-modal matching problem which is typically
solved by learning a joint embedding space where the semantic content shared between the
photo
and sketch modalities are preserved. However, a fundamental challenge in SBIR has been
largely
ignored so far, that is, sketches are drawn by humans and considerable style variations
exist
between different users. An effective SBIR model needs to explicitly account for this style
diversity, and crucially to generalise to unseen user styles. To this end, a novel
style-agnostic SBIR model is proposed. Different from existing models, a cross-modal
variational
autoencoder (VAE) is employed to explicitly disentangle each sketch into a semantic content
part
shared with the corresponding photo and a style part unique to the sketcher. Importantly, to
make our model dynamically adaptable to any unseen user styles, we propose to meta-train our
cross-modal VAE by adding two style-adaptive components: a set of feature transformation
layers
to its encoder and a regulariser to the disentangled semantic content latent code. With this
meta-learning framework, our model can not only disentangle the cross-modal shared semantic
content for SBIR, but can adapt the disentanglement to any unseen user styles as well,
making
the SBIR model truly style-agnostic. Extensive experiments show that our style-agnostic
model
yields state-of-the-art performance for both category-level and instance-level SBIR.
@InProceedings{stylemeup,
author = {Aneeshan Sain and Ayan Kumar Bhunia and Yongxin Yang and Tao Xiang and Yi-Zhe
Song},
title = {StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}
|
|
|
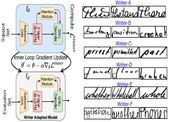
MetaHTR: Towards Writer-Adaptive Handwritten Text Recognition
Ayan Kumar Bhunia
, Shuvozit Ghose, Amandeep Kumar,
Pinaki Nath Chowdhury, Aneeshan Sain,
Yi-Zhe Song
.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
),
2021
Abstract
/
arXiv
/
BibTex
Handwritten Text Recognition (HTR) remains a challenging problem to date, largely due to
the
varying writing styles that exist amongst us. Prior works however generally operate with the
assumption that there is a limited number of styles, most of which have already been
captured
by
existing datasets. In this paper, we take a completely different perspective -- we work on
the
assumption that there is always a new style that is drastically different, and that we will
only
have very limited data during testing to perform adaptation. This results in a commercially
viable solution -- the model has the best shot at adaptation being exposed to the new style,
and
the few samples nature makes it practical to implement. We achieve this via a novel
meta-learning framework which exploits additional new-writer data through a support set, and
outputs a writer-adapted model via single gradient step update, all during inference. We
discover and leverage on the important insight that there exists few key characters per
writer
that exhibit relatively larger style discrepancies. For that, we additionally propose to
meta-learn instance specific weights for a character-wise cross-entropy loss, which is
specifically designed to work with the sequential nature of text data. Our writer-adaptive
MetaHTR framework can be easily implemented on the top of most state-of-the-art HTR models.
Experiments show an average performance gain of 5-7% can be obtained by observing very few
new
style data. We further demonstrate via a set of ablative studies the advantage of our meta
design when compared with alternative adaption mechanisms.
@InProceedings{metahtr,
author = {Ayan Kumar Bhunia and Shuvozit Ghose, Amandeep Kumar and Pinaki Nath Chowdhury and
Aneeshan Sain and Yi-Zhe Song},
title = {MetaHTR: Towards Writer-Adaptive Handwritten Text Recognition},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}
}
|
|
|
Pixelor: A Competitive Sketching AI Agent. So you think you can beat me?
Ayan Kumar Bhunia*
, Ayan Das*, Umar Riaz Muhammad*,
Yongxin Yang, Timothy M. Hospedalis,
Tao Xiang, Yulia Gryaditskaya, Yi-Zhe
Song
.
SIGGRAPH Asia
, 2020.
Abstract
/
Code
/
arXiv
/
BibTex
/
Try Online Demo
(*equal contribution)
We present the first competitive drawing agent Pixelor that exhibits human-level
performance
at a Pictionary-like sketching game, where the participant whose sketch is recognized first
is
a
winner. Our AI agent can autonomously sketch a given visual concept, and achieve a
recognizable
rendition as quickly or faster than a human competitor. The key to victory for the agent is
to
learn the optimal stroke sequencing strategies that generate the most recognizable and
distinguishable strokes first. Training Pixelor is done in two steps. First, we infer the
optimal stroke order that maximizes early recognizability of human training sketches.
Second,
this order is used to supervise the training of a sequence-to-sequence stroke generator. Our
key
technical contributions are a tractable search of the exponential space of orderings using
neural sorting; and an improved Seq2Seq Wasserstein (S2S-WAE) generator that uses an
optimal-transport loss to accommodate the multi-modal nature of the optimal stroke
distribution.
Our analysis shows that Pixelor is better than the human players of the Quick, Draw! game,
under
both AI and human judging of early recognition. To analyze the impact of human competitors’
strategies, we conducted a further human study with participants being given unlimited
thinking
time and training in early recognizability by feedback from an AI judge. The study shows
that
humans do gradually improve their strategies with training, but overall Pixelor still
matches
human performance. We will release the code and the dataset, optimized for the task of early
recognition, upon acceptance.
@InProceedings{sketchxpixelor,
author = {Ayan Kumar Bhunia and Ayan Das and Umar Riaz Muhammad and Yongxin Yang and Timothy
M.
Hospedales and Tao Xiang and Yulia Gryaditskaya and Yi-Zhe Song},
title = {Pixelor: A Competitive Sketching AI Agent. So you think you can beat me?},
booktitle = {Siggraph Asia},
month = {November},
year = {2020}
}
|
|
|
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image
Retrieval
Aneeshan Sain,
Ayan Kumar Bhunia
, Yongxin Yang,
Tao Xiang, Yi-Zhe Song
.
British Machine Vision Conference (
BMVC
), 2020.
Abstract
/
arXiv
/
BibTex
(Oral Presentation)
Sketch as an image search query is an ideal alternative to text in capturing the
fine-grained
visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have
demonstrated the importance of tackling the unique traits of sketches as opposed to photos,
e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this
paper,
we
study a further trait of sketches that has been overlooked to date, that is, they are
hierarchical in terms of the levels of detail -- a person typically sketches up to various
extents of detail to depict an object. This hierarchical structure is often visually
distinct.
In this paper, we design a novel network that is capable of cultivating sketch-specific
hierarchies and exploiting them to match sketch with photo at corresponding hierarchical
levels.
In particular, features from a sketch and a photo are enriched using cross-modal
co-attention,
coupled with hierarchical node fusion at every level to form a better embedding space to
conduct
retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts
by
a
significant margin.
@InProceedings{sain2020crossmodal,
author = {Aneeshan Sain and Ayan Kumar Bhunia and Yongxin Yang and Tao Xiang and Yi-Zhe
Song},
title = {Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image
Retrieval},
booktitle = {BMVC},
month = {September},
year = {2020}
}
|
|
|
Fine-grained visual classification via progressive multi-granularity training
of
jigsaw patches
Ruoyi Du, Dongliang Chang,
Ayan Kumar Bhunia
, Jiyang Xie,
Zhanyu Ma, Yi-Zhe Song
, Jun Guo
.
European Conference on Computer Vision (
ECCV
), 2020.
Abstract
/
Code/
arXiv
/
BibTex
Fine-grained visual classification (FGVC) is much more challenging than traditional
classification tasks due to the inherently subtle intra-class object variations. Recent works
are
mainly part-driven (either explicitly or implicitly), with the assumption that fine-grained
information naturally rests within the parts. In this paper, we take a different stance, and
show that part operations are not strictly necessary -- the key lies with encouraging the
network to learn at different granularities and progressively fusing multi-granularity
features
together. In particular, we propose: (i) a progressive training strategy that effectively
fuses
features from different granularities, and (ii) a random jigsaw patch generator that
encourages
the network to learn features at specific granularities. We evaluate on several standard
FGVC
benchmark datasets, and show the proposed method consistently outperforms existing
alternatives
or delivers competitive results.
@InProceedings{du2020fine,
author = {Du, Ruoyi and Chang, Dongliang and Bhunia, Ayan Kumar and Xie, Jiyang and Song,
Yi-Zhe
and Ma, Zhanyu and Guo, Jun},
title = {Fine-grained visual classification via progressive multi-granularity training of
jigsaw
patches},
booktitle = {ECCV},
month = {August},
year = {2020}
}
|
|
|
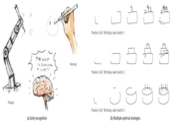
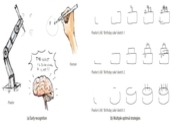
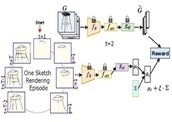
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Ayan Kumar Bhunia
, Yongxin Yang, Timothy M. Hospedalis,
Tao Xiang, Yi-Zhe Song.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
), 2020.
Abstract
/
Code
/
arXiv
/
BibTex
(Oral Presentation)
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a
particular photo instance given a user's query sketch. Its widespread applicability is
however
hindered by the fact that drawing a sketch takes time, and most people struggle to draw a
complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR
framework
to tackle these challenges, with the ultimate goal of retrieving the target photo with the
least
number of strokes possible. We further propose an on-the-fly design that starts retrieving
as
soon as the user starts drawing. To accomplish this, we devise a reinforcement learning
based
cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over
a
complete sketch drawing episode. Additionally, we introduce a novel reward scheme that
circumvents the problems related to irrelevant sketch strokes, and thus provides us with a
more
consistent rank list during the retrieval. We achieve superior early-retrieval efficiency
over
state-of-the-art methods and alternative baselines on two publicly available fine-grained
sketch
retrieval datasets.
@InProceedings{bhunia2020sketch,
author = {Ayan Kumar Bhunia and Yongxin Yang and Timothy M. Hospedales and Tao Xiang and
Yi-Zhe
Song},
title = {Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
|
|
|
Handwriting Recognition in Low-Resource Scripts Using Adversarial Learning
Ayan Kumar Bhunia
, Abhirup Das, Ankan Kumar Bhunia,
Perla Sai Raj Kishore, Partha Pratim Roy.
IEEE Conference on Computer Vision and Pattern Recognition (
CVPR
), 2019
Abstract
/
Code
/
arXiv
/
BibTex
Handwritten Word Recognition and Spotting is a challenging field dealing with handwritten
text
possessing irregular and complex shapes. The design of deep neural network models makes it
necessary to extend training datasets in order to introduce variations and increase the
number
of samples; word-retrieval is therefore very difficult in low-resource scripts. Much of the
existing literature comprises preprocessing strategies which are seldom sufficient to cover
all
possible variations. We propose an Adversarial Feature Deformation Module (AFDM) that learns
ways to elastically warp extracted features in a scalable manner. The AFDM is inserted
between
intermediate layers and trained alternatively with the original framework, boosting its
capability to better learn highly informative features rather than trivial ones. We test our
meta-framework, which is built on top of popular word-spotting and word-recognition
frameworks
and enhanced by AFDM, not only on extensive Latin word datasets but also on sparser Indic
scripts. We record results for varying sizes of training data, and observe that our enhanced
network generalizes much better in the low-data regime; the overall word-error rates and mAP
scores are observed to improve as well.
@InProceedings{Bhunia_2019_CVPR,
author = {Bhunia, Ayan Kumar and Das, Abhirup and Bhunia, Ankan Kumar and Kishore, Perla Sai
Raj
and Roy, Partha Pratim},
title = {Handwriting Recognition in Low-Resource Scripts Using Adversarial Learning},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2019}
}
|
|
|
Improving Document Binarization via Adversarial Noise-Texture Augmentation
Ankan Kumar Bhunia,
Ayan Kumar Bhunia
,
Aneeshan Sain, Partha Pratim Roy.
IEEE Conference on Image Processing (
ICIP
), 2019
Abstract
/
Code
/
arXiv
/
BibTex
(Top 10% Papers)
Binarization of degraded document images is an elementary step in most of the problems in
document image analysis domain. The paper re-visits the binarization problem by introducing
an
adversarial learning approach. We construct a Texture Augmentation Network that transfers
the
texture element of a degraded reference document image to a clean binary image. In this way,
the
network creates multiple versions of the same textual content with various noisy textures,
thus
enlarging the available document binarization datasets. At last, the newly generated images
are
passed through a Binarization network to get back the clean version. By jointly training the
two
networks we can increase the adversarial robustness of our system. Also, it is noteworthy
that
our model can learn from unpaired data. Experimental results suggest that the proposed
method
achieves superior performance over widely used DIBCO datasets.
@inproceedings{bhunia2019improving,
title={Improving document binarization via adversarial noise-texture augmentation},
author={Bhunia, Ankan Kumar and Bhunia, Ayan Kumar and Sain, Aneeshan and Roy, Partha Pratim},
booktitle={2019 IEEE International Conference on Image Processing (ICIP)},
pages={2721--2725},
year={2019},
organization={IEEE}
}
|
|
|
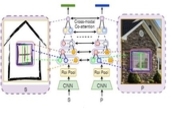
A Deep One-Shot Network for Query-based Logo Retrieval
Ayan Kumar Bhunia
, Ankan Kumar Bhunia,
Shuvozit Ghose, Abhirup Das, Partha
Pratim
Roy, Umapada Pal
Pattern Recognition (
PR
), 2019
Abstract
/
Code
/
Third Party Implementation
/
arXiv
/
BibTex
Logo detection in real-world scene images is an important problem with applications in
advertisement and marketing. Existing general-purpose object detection methods require large
training data with annotations for every logo class. These methods do not satisfy the
incremental demand of logo classes necessary for practical deployment since it is
practically
impossible to have such annotated data for new unseen logo. In this work, we develop an
easy-to-implement query-based logo detection and localization system by employing a one-shot
learning technique using off the shelf neural network components. Given an image of a query
logo, our model searches for logo within a given target image and predicts the possible
location
of the logo by estimating a binary segmentation mask. The proposed model consists of a
conditional branch and a segmentation branch. The former gives a conditional latent
representation of the given query logo which is combined with feature maps of the
segmentation
branch at multiple scales in order to obtain the matching location of the query logo in a
target
image. Feature matching between the latent query representation and multi-scale feature maps
of
segmentation branch using simple concatenation operation followed by 1 × 1 convolution layer
makes our model scale-invariant. Despite its simplicity, our query-based logo retrieval
framework achieved superior performance in FlickrLogos-32 and TopLogos-10 dataset over
different
existing baseline methods.
@article{bhunia2019deep,
title={A Deep One-Shot Network for Query-based Logo Retrieval},
author={Bhunia, Ayan Kumar and Bhunia, Ankan Kumar and Ghose, Shuvozit and Das, Abhirup and
Roy,
Partha Pratim and Pal, Umapada},
journal={Pattern Recognition},
pages={106965},
year={2019},
publisher={Elsevier}}
|
|
|
User Constrained Thumbnail Generation Using Adaptive Convolutions
Perla Sai Raj Kishore,
Ayan Kumar Bhunia
, Shovozit Ghose,
Partha Pratim Roy
International Conference on Acoustics, Speech and Signal Processing (
ICASSP
), 2019
Abstract
/
Code
/
arXiv
/
BibTex
(Oral Presentation)
Thumbnails are widely used all over the world as a preview for digital images. In this work
we
propose a deep neural framework to generate thumbnails of any size and aspect ratio, even
for
unseen values during training, with high accuracy and precision. We use Global Context
Aggregation (GCA) and a modified Region Proposal Network (RPN) with adaptive convolutions to
generate thumbnails in real time. GCA is used to selectively attend and aggregate the global
context information from the entire image while the RPN is used to generate candidate
bounding
boxes for the thumbnail image. Adaptive convolution eliminates the difficulty of generating
thumbnails of various aspect ratios by using filter weights dynamically generated from the
aspect ratio information. The experimental results indicate the superior performance of the
proposed model 1 over existing state-of-the-art techniques.
@inproceedings{kishore2019user,
title={User Constrained Thumbnail Generation Using Adaptive Convolutions},
author={Kishore, Perla Sai Raj and Bhunia, Ayan Kumar and Ghose, Shuvozit and Roy, Partha
Pratim},
booktitle={ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal
Processing (ICASSP)},
pages={1677--1681},
year={2019},
organization={IEEE}
}
|
|
|
Texture Synthesis Guided Deep Hashing for Texture Image Retrieval
Ayan Kumar Bhunia
,
Perla Sai Raj Kishore,
Pranay Mukherjee,
Abhirup Das,
Partha Pratim Roy
IEEE Winter Conference on Applications of Computer Vision (
WACV
), 2019
Abstract
/
arXiv
/
BibTex
/
Video Presentation
With the large scale explosion of images and videos over the internet, efficient hashing
methods
have been developed to facilitate memory and time efficient retrieval of similar images.
However, none of the existing works use hashing to address texture image retrieval mostly
because of the lack of sufficiently large texture image databases. Our work addresses this
problem by developing a novel deep learning architecture that generates binary hash codes
for
input texture images. For this, we first pre-train a Texture Synthesis Network (TSN) which
takes
a texture patch as input and outputs an enlarged view of the texture by injecting newer
texture
content. Thus it signifies that the TSN encodes the learnt texture specific information in
its
intermediate layers. In the next stage, a second network gathers the multi-scale feature
representations from the TSN’s intermediate layers using channel-wise attention, combines
them
in a progressive manner to a dense continuous representation which is finally converted into
a
binary hash code with the help of individual and pairwise label information. The new
enlarged
texture patches from the TSN also help in data augmentation to alleviate the problem of
insufficient texture data and are used to train the second stage of the network. Experiments
on
three public texture image retrieval datasets indicate the superiority of our texture
synthesis
guided hashing approach over existing state-of-the-art methods.
@inproceedings{bhunia2019texture,
title={Texture synthesis guided deep hashing for texture image retrieval},
author={Bhunia, Ayan Kumar and Perla, Sai Raj Kishore and Mukherjee, Pranay and Das, Abhirup
and
Roy, Partha Pratim},
booktitle={2019 IEEE Winter Conference on Applications of Computer Vision (WACV)},
pages={609--618},
year={2019},
organization={IEEE}
}
|
|
|
Script identification in natural scene image and video frames using an
attention
based Convolutional-LSTM network
Ankan Kumar Bhunia, Aishik Konwer,
Ayan Kumar Bhunia
,
Abir Bhowmick, Partha Pratim Roy,
Umapada
Pal
Pattern Recognition (
PR
), 2019
Abstract
/
Code
/
arXiv
/
BibTex
Script identification plays a significant role in analysing documents and videos. In this
paper,
we focus on the problem of script identification in scene text images and video scripts.
Because
of low image quality, complex background and similar layout of characters shared by some
scripts
like Greek, Latin, etc., text recognition in those cases become challenging. In this paper,
we
propose a novel method that involves extraction of local and global features using CNN-LSTM
framework and weighting them dynamically for script identification. First, we convert the
images
into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are
calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these
weights with corresponding CNN to yield local features. Global features are also extracted
from
last cell state of LSTM. We employ a fusion technique which dynamically weights the local
and
global features for an individual patch. Experiments have been done in four public script
identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework
achieves
superior results in comparison to conventional methods.
@article{bhunia2019script,
title={Script identification in natural scene image and video frames using an attention based
convolutional-LSTM network},
author={Bhunia, Ankan Kumar and Konwer, Aishik and Bhunia, Ayan Kumar and Bhowmick, Abir and
Roy,
Partha P and Pal, Umapada},
journal={Pattern Recognition},
volume={85},
pages={172--184},
year={2019},
publisher={Elsevier}
}
|

|